10 - Agregace
Elasticsearch není jen vyhledávací engine, je také analytický engine. Pomocí agregací lze získat přehled o datech uložených v Elasticsearch.
Zápis agregací
Agregace se zapisují do těla requestu pod klíč aggregations, případně zkráceně aggs:
xxxxxxxxxxGET _search{ "query": {}, "aggs": { }}Agregací je možné počítat více zároveň:
xxxxxxxxxxGET _search{ "query": {}, "aggs": { "aggregations" : { "<aggregation_name_1>" : { "<aggregation_type_1>" : { } }, "<aggregation_name_2>" : { } } }}Nebo je možné agregace zanořovat:
xxxxxxxxxxGET _search{ "query": {}, "aggs": { "aggregations" : { "<aggregation_name_1>" : { "<aggregation_type_1>" : { }, "<aggregation_name_2>" : { } } } }}Název agregace si lze zvolit libovolný. Pokud jsou agregace zanořeny, počítají se vnořené agregace pro jednotlivé skupiny agregací na vyšší úrovni. Pokud budeme chtít spočítat průměrnou cenu objednávky každý den, napíšeme nepjrve agregaci, která data rozdělí po dnech (bucket - např. date_histogram) a následně použijeme agregaci vnořenou (metric - např. avg).
S agregacemi se budeme setkávat také v Kibaně - veškeré vizualizace získávají data právě pomocí vizualizací.
Agregací existuje několik druhů, které se liší způsobem, kterým pracují s daty:
Bucket aggregations
Prvním typem agregací jsou tzv. bucket agregace. Ty seskupí hodnoty ve vyhledaných dokumentech podle daných pravidel do skupin. Jde o alternativu k GROUP BY relačních databází.
terms: seskupení podle hodnoty tokenudate_histogram: seskupení podle data/času do časových úsekůfilter: seskupení podle uživatelsky definovaných filtrůrange: seskupení podle uživatelsky definovaných rozsahů (číselných nebo časových)
Metric aggregations
Druhým typem agregací jsou ty, které provádějí statistické výpočty nad nalezenými produkty - minima, maxima nebo průměry.
avg: průměrmax: maximummin: minimumstats: více statistických výpočtů zároveň
Pipeline aggregations
Speciální druh agregací, které namísto práce s dokumenty pracují s výsledky agregací. Obecně existují dva typy takových agregací:
Parent agregace pracují s výsledky nadřazených agregací a přidávají do nich další výsledky výpočtů. Zpravidla je třeba uvést cestu, s kterou nadřazenou agregací pracují jako buckets_path.
Sibling agregace pracují s výsledky agregací na shodné úrovni.
Příkladem pipeline agregace může být cumulative_sum, která přičítává hodnoty jednotlivých výsledků agregace. Lze ji použít například pro výpočet stavu účtu na základě jednotlivých transakcí:
xxxxxxxxxxGET /_search{ "aggs": { "my_agg_days": { "date_histogram": { "field":"date", "calendar_interval":"day" }, "aggs": { "my_agg_sum": { "sum": {"field": "amount"} }, "my_agg_balance": { "cumulative_sum": {"buckets_path": "my_agg_sum"} } } } }}Dalším příkladem může být bucket_sort . Pokud bychom chtěli seřadit měsíce podle největších zústatků na účtu, bylo by to možné následujícím způsobem:
xxxxxxxxxxGET /_search{ "aggs": { "my_agg_days": { "date_histogram": { "field": "date", "calendar_interval": "day" }, "aggs": { "my_agg_sum": { "sum": {"field": "amount"} }, "my_agg_top_3_days": { "bucket_sort": { "sort": [ {"my_agg_sum": {"order": "desc"}} ], "size": 3 } } } } }}
Post filter
V případě kombinace vyhledávání a agregací je třeba někdy vypočítat agregace před samotnou filtrací. V takovém případě je možné tyto filtrace přesunout do sekce post_filter zapsané na najvyšší úrovni request body. Příkladem může být e-shop, kde nejprve spočítám data pro filtry pomocí agregací a následně pomocí post_filter vyfiltruji data podle zaškrtaných hodnot v uživatelském filtru.
xxxxxxxxxxGET _search{ "query": { // <= query spuštěná před agregacemi "term": { "field": "value" } }, "aggs": { }, "post_filter": { // <= documents filtrovány po výpočtu agregací "term": { "field": "value" } }}
Úkol: Agregace
V indexu kibana_sample_data_ecommerce:
Vypišteemailadresy, které vytvořily nejvíc objednávekPro každý den v týdnu (poleday_of_weeka použijte agregaciterms) zjistěte průměrnou cenu objednávky (s použitím poletaxful_total_price)Vyfiltrujte data podle polegeoip.continent_names hodnotouNorth America(můžete použíttermquery); poté pro každé pohlaví (customer_gender) spočítejte průměrný počet produktů (použijteavgagregaci a poletotal_unique_products)
Na stránce s materiály ke kurzu přejděte do složky data, kde naleznete dva soubory, které postupně otevřete a zkopírujte do dev tools v kibaně:
shop-orders-demo-mapping- nastaví mapováníshop-orders-demo-data- naimportuje data
Následně napište queries, kde s pomocí agregací:
Vypište jména zákazníků (pole
customer.name), které vytvořily nejvíc objednávekPro každý druh platby (
payment_method) zjistěte průměrnou cenu objednávky (s použitím poletotal_amount)
Kibana - vizualizace
Kibana využívá agregace pro tvorbu vizualizací. Ty je možné vytvořit prostřednictvím Visualize Library:
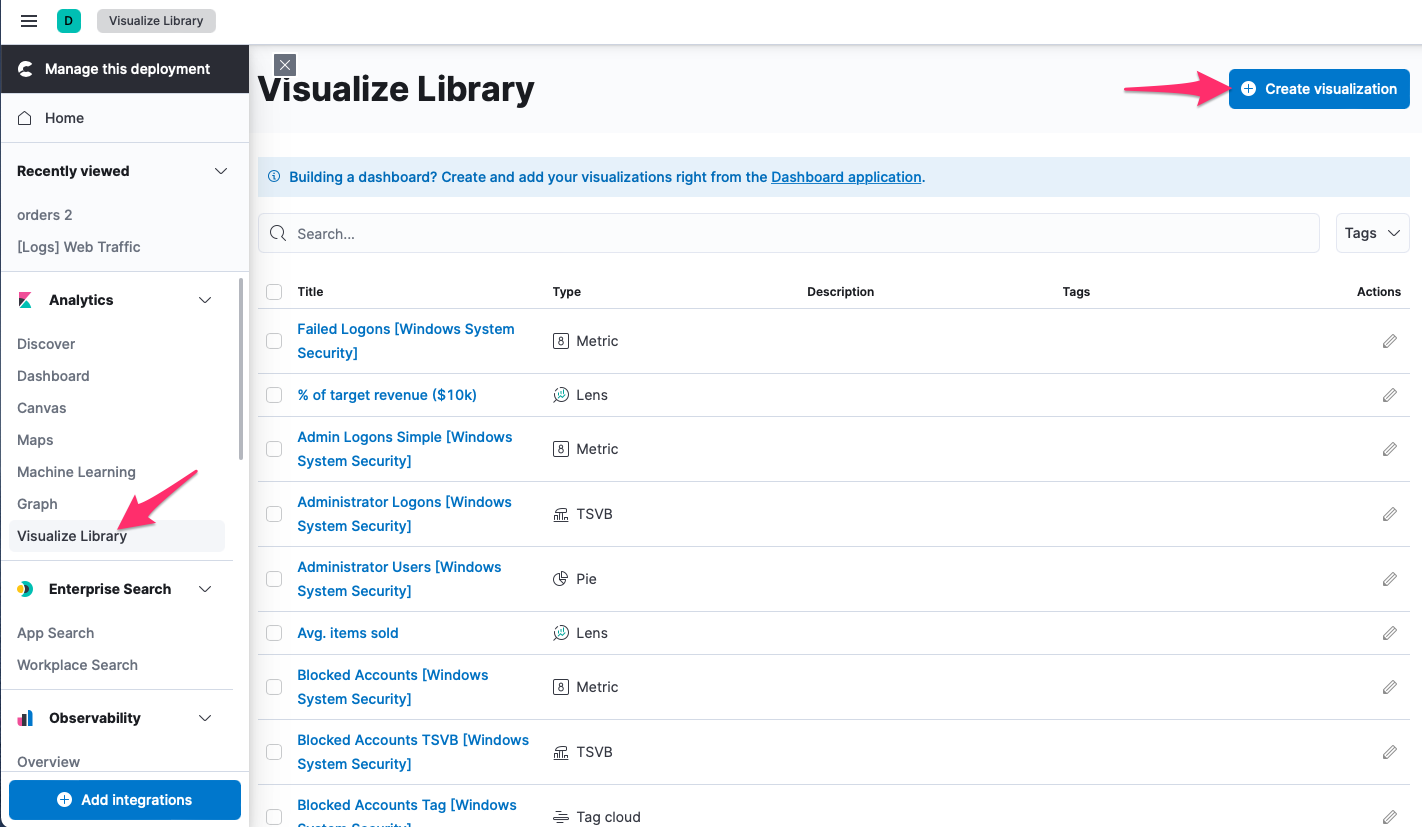
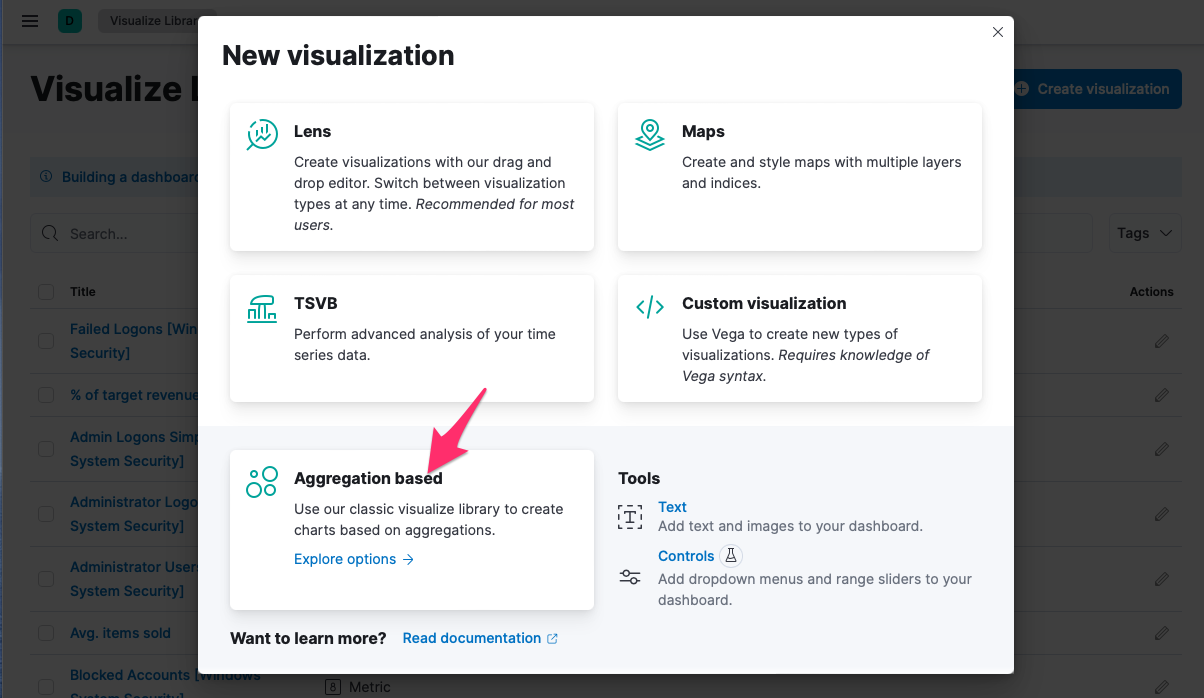
Zvolte Aggregation based visualizations:
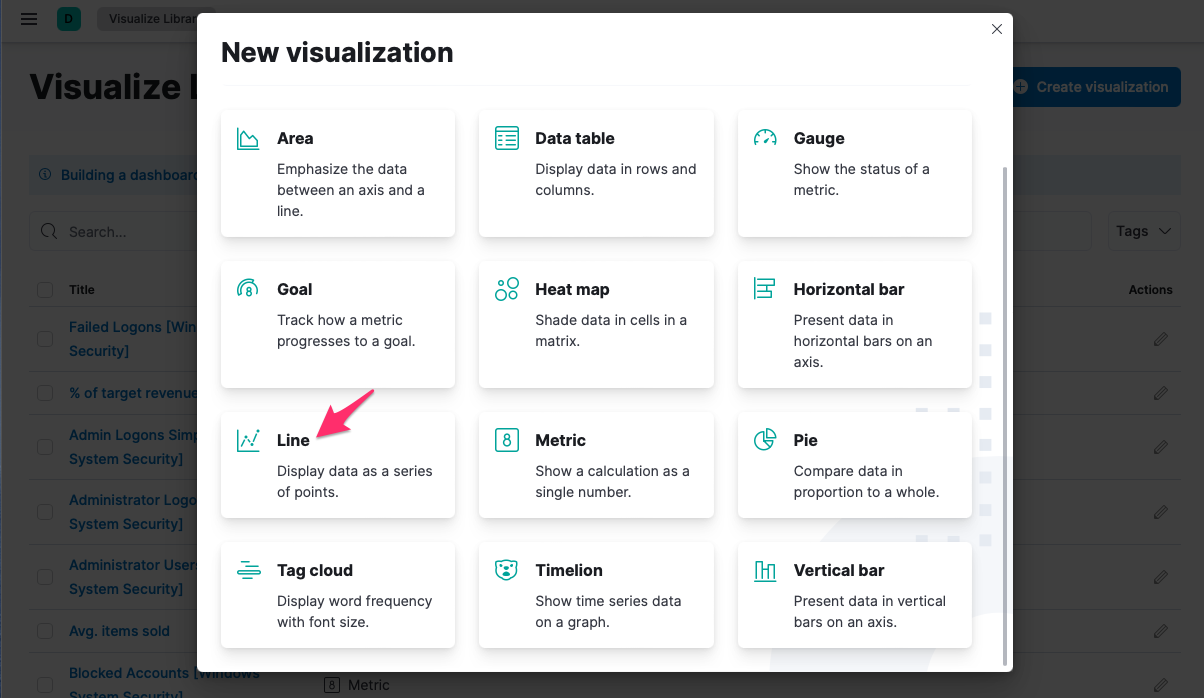
Poté zvolte libovolný typ agregace, např. Line:
V posledním kroku zvolte data, která mají být pomocí vizualizace zobrazena - Data view, nebo uložená tabulka Discover:
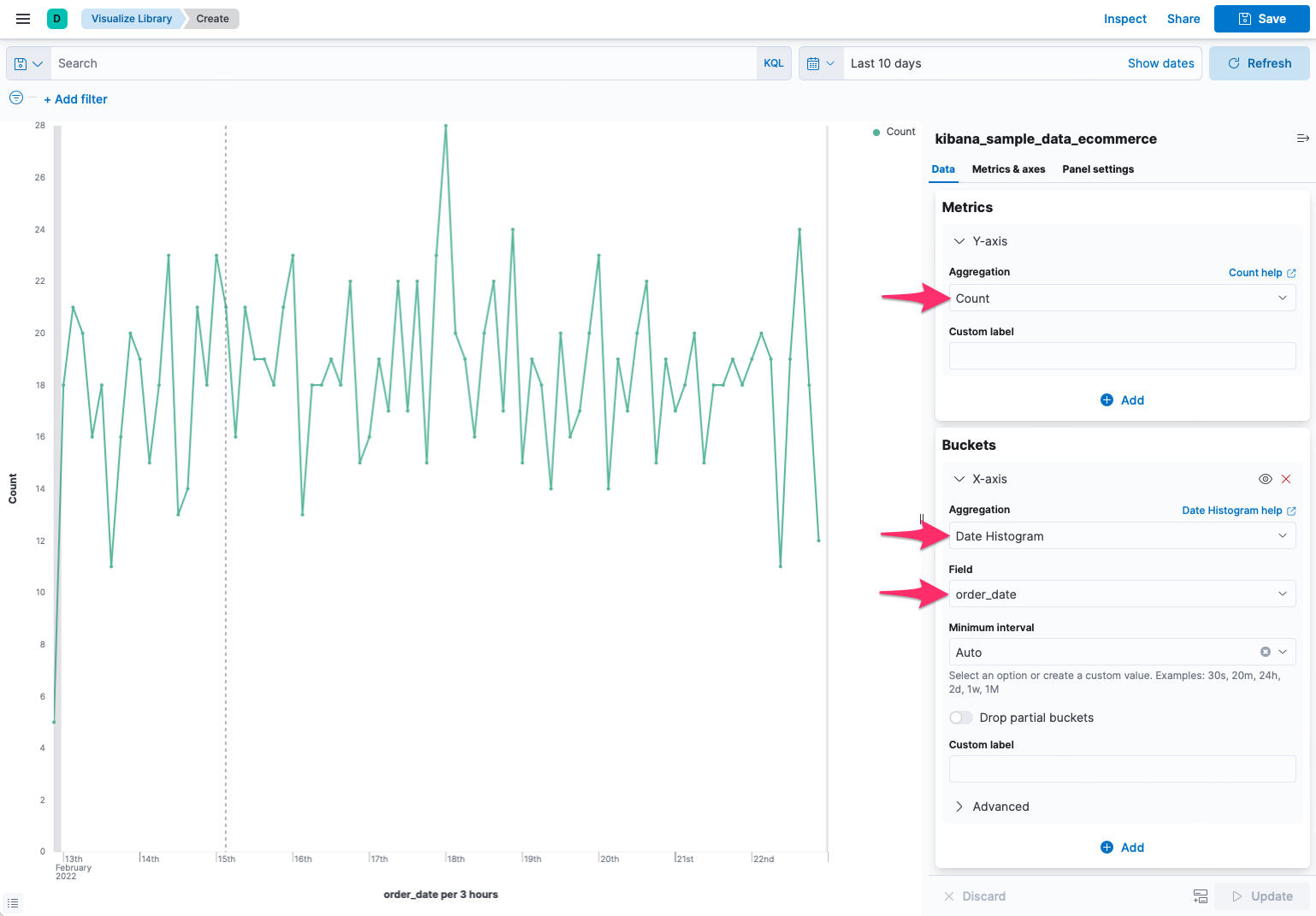
V nově vytvořené vizualizaci lze zvolit metrickou agregaci, která bude reprezentována na ose Y a bucket agregaci, která se promítne na osu X.
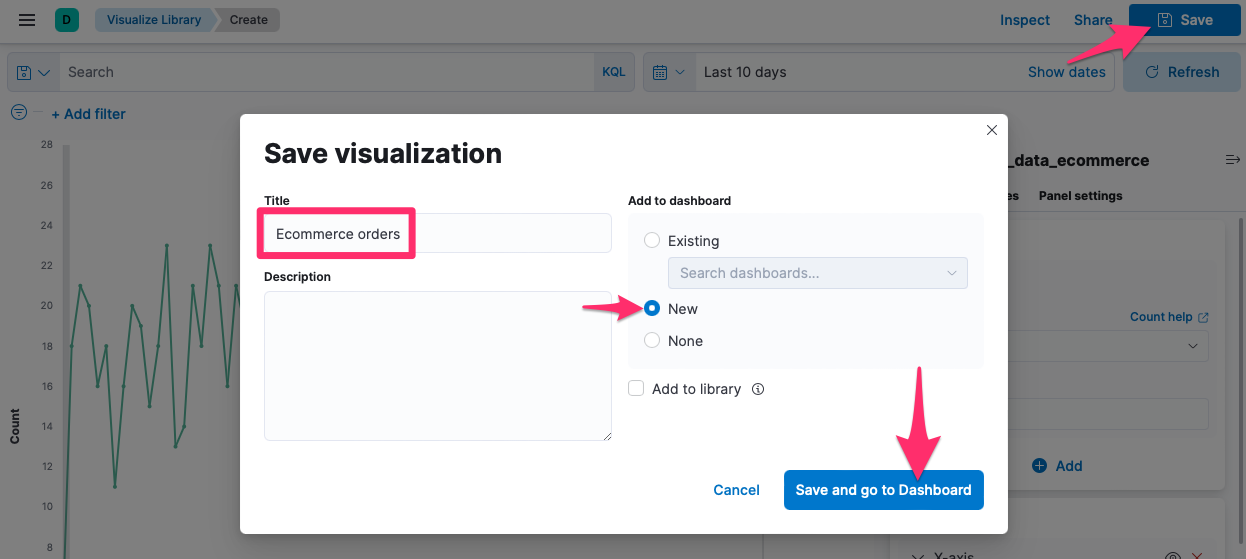
Kompletní vizualizaci je možné uložit a případně přidat na dashboard:
Dashboard je stránka v Kibaně sestávající z více vizualizací: