05 - Práce s indexy, hromadné operace
Vytvoření indexu
Vytvořit index je možné ještě před tím, než do něj uložíme data - HTTP metodou PUT následovanou názvem indexu. Pokud poté vypíšeme seznam indexů, měl by na něm přibýt nově vytvořený index:
xxxxxxxxxx# Create an index:PUT users# Check result:GET _cat/indices?v
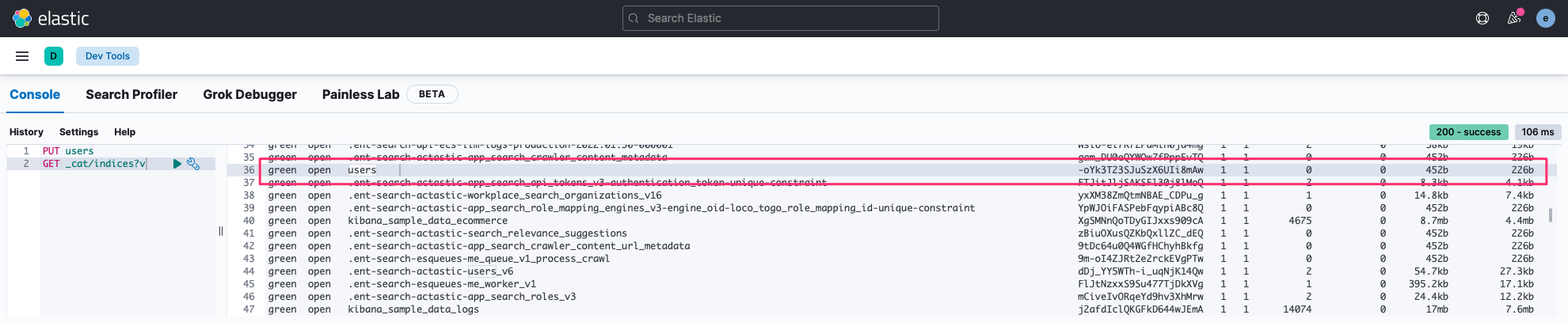
Při vytváření indexu můžeme indexu přidat různé nastavení. Například lze definovat počet shardů pomocí index.number_of_shards respektive index.number_of_replicas. Pokud se však nyní pokusíte znovu vytvořit index users, operace skončí chybou, protože takto nazvaný index již existuje. Jednou z možností je jej smazat (použít HTTP metodu DELETE), čímž také dojde ke smazání veškerého obsahu indexu:
xxxxxxxxxx// Nejprve smažeme stávající index - pozor, smažou se i veškerá data, která obsahujeDELETE users
// Nyní již lze index vytvořitPUT users{ "settings": { "index.number_of_shards": 1, // <= jeden primární shard "index.number_of_replicas": 0 // <= žádné replika shardy }}Pokud chceme pouze změnit počet replik existujícího indexu, je to možné provést i po vytvoření indexu následujícím příkazem:
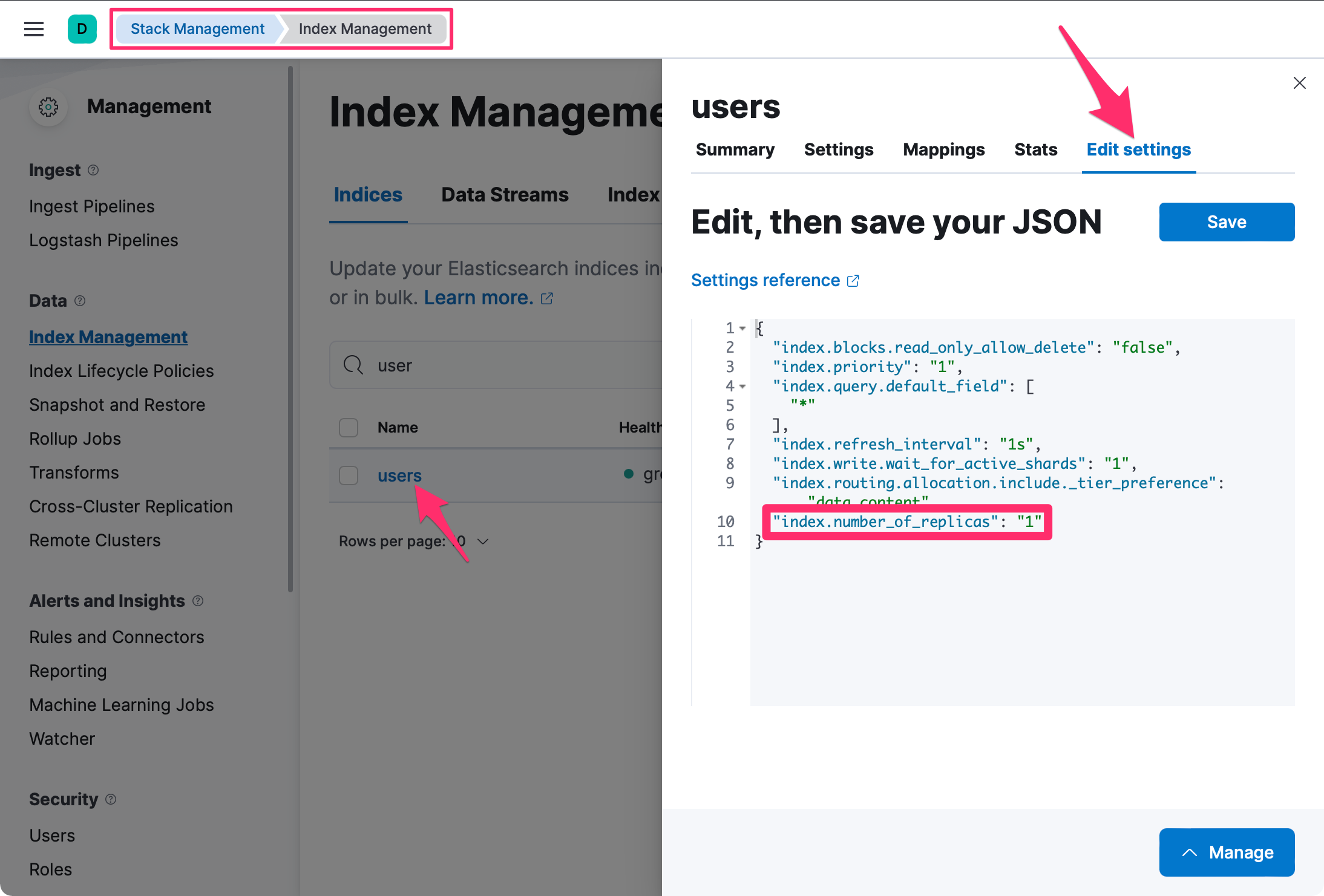
xxxxxxxxxxPUT users/_settings{ "index.number_of_replicas": 0}Nastavení indexů je možné měnit také skrz grafické rozhraní - v Kibaně pod Stack Management > Data > Index Management stačí zvolit daný index a nastavení změnit:
Bulk API - hromadné operace
Operace s dokumenty nemusíme provádět po jednom requestu na dokument, je možné využít _bulk api, které umí v rámci jednoho requestu zpracovat několik operací. Slouží k tomu endpoint _bulk, před kterým je uveden název indexu. Vstupní data jsou zadávána tak, že na každém řádku je jedna požadovaná operace nebo dokument.
xxxxxxxxxxPOST _bulk{"index": {"_index": "users", "_id": "5"}}{"name": "John Brown", "age": 35}{"create": {"_index": "users"}}{"name": "Sophia Miller"}Kromě ukládání dokumentů je možné je hromadně upravovat a mazat:
xxxxxxxxxxPOST _bulk{"update": {"_index": "users", "_id": "5"}}{"doc": {"age": 37}}{"delete": {"_index": "users", "_id": "6"}}Jde o efektivní způsob, jak do Elasticsearch uložit větší množství dat, protože se minimalizuje počet navazování spojení po síti. Pokud některá dílčí operace skončí chybou, neznamená to ještě chybu celého requestu - v response se dozvíme, kolik dílčích operací skončilo (ne)úspěšně.
Modifikace a mazání více dokumentů
Dalším způsobem modifikace dokumentů je využití Update by query API, které vyžaduje zapsaný skript popisující logiku změny jednotlivého dokumentu:
xxxxxxxxxxPOST users/_update_by_query{ "query": { "exists": { "field": "age" } }, "script" : "ctx._source.age += 2",}Ke smazání některých dokumentů v rámci indexu lze využít Delete by query API. Zde je nutné uvést query, která určí, které dokumenty mají být smazány:
xxxxxxxxxxPOST users/_delete_by_query{ "query": { "term": { "age": 37 } }}
Reindexace
Index obsahuje několik konfigurací, které není možné po jeho vytvoření změnit. Problém nastává i ve chvíli, kdy do indexu uložíme dokument, jehož pole se uloží jako jeden datový typ (například text), ale později zjistíme, že by měl mít jiný datový typ (například datum) a již není možné jej změnit.
Pokud chceme takovou úpravu provést v rámci Elasticsearch, je nutné nejprve ručně vytvořit nový index se správným nastavením a následně zkopírovat pomocí reindexace data z původního indexu do nového. Pro tuto operaci je k dispozici endpoint _reindex:
xxxxxxxxxxPOST _reindex{ "source": { "index": "users" }, "dest": { "index": "users-updated" }}Tento endpoint budeme využívat při změnách v nastavení indexu souvisejících s vyhledáváním. Je možné jej využít i ve specifičtějších případech, kdy chceme přeindexovat jen část dokumentů, nebo naopak dostat dokumenty z více indexů do jednoho. V neposlední řadě je možné jej použít pro přenos dat mezi různými clustery, například ze staging prostředí do lokálního.
Při reindexaci se pouze přenáší data, nepřenáší se nastavení indexu jako je počet shardů, replik, nebo mapping. Pokud tedy chceme, aby měl nově vytvářený index nějaké jiné nastavení, než výchozí, je třeba nejprve vytvořit index s požadovaným nastavením a následně do něj data reindexovat.
Aliasy
V praxi dochází ke změnám v nastavení indexu a následné reindexaci, než ale tyto operace proběhnou, nemůžeme si často dovolit mít index jen částečně funkční, obsahující neúplná data. Pro tento účel je možné využít aliasu, kdy lze jednomu indexu přiřadit alternativní název, pod kterým je dostupný.
Předpokládejme, že data jsou uložena v indexu user_v1, ale došlo k změně v nastavení indexu a je tak třeba vytvořit nový index user_v2 a nakopírovat do něj stávající data. Můžeme si vytvořit alias, který user, který bude směrovat vždy na aktuální index:
xxxxxxxxxx// vytvoření indexuPUT user_v1
// přidání aliasuPOST _aliases{ "actions": [ {"add": {"index": "user_v1", "alias": "user"}} ]}
// vytvoření nového indexuPUT user_v2
// překlopení aliasu z starého indexu na novýPOST _aliases{ "actions": [ {"remove": {"index": "user_v1", "alias": "user"}}, {"add": {"index": "user_v2", "alias": "user"}} ]}
// později můžeme nepoužívaný index smazatDELETE user_v1Tato operace je atomická, takže není třeba se obávat, že by byla data nějakou dobu nedostupná.
Práce s více indexy
Při vyhledávání v Elasticsearch můžeme specifikovat, ve kterých indexech se má vyhledávat. Dosud jsme vždy uváděli právě jeden index, ale můžeme jich vyjmenovat více (a oddělit názvy čárkou):
xxxxxxxxxxGET user,customer,subscription/_search
Dále můžeme použít znak *, který zastoupí libovolné znaky v libovolném počtu. Již jsme jej využili při vytváření sablony, stejně jej můžeme využít pro vyhledávání napříč všemi indexy v Elasticsearch:
xxxxxxxxxxGET */_search
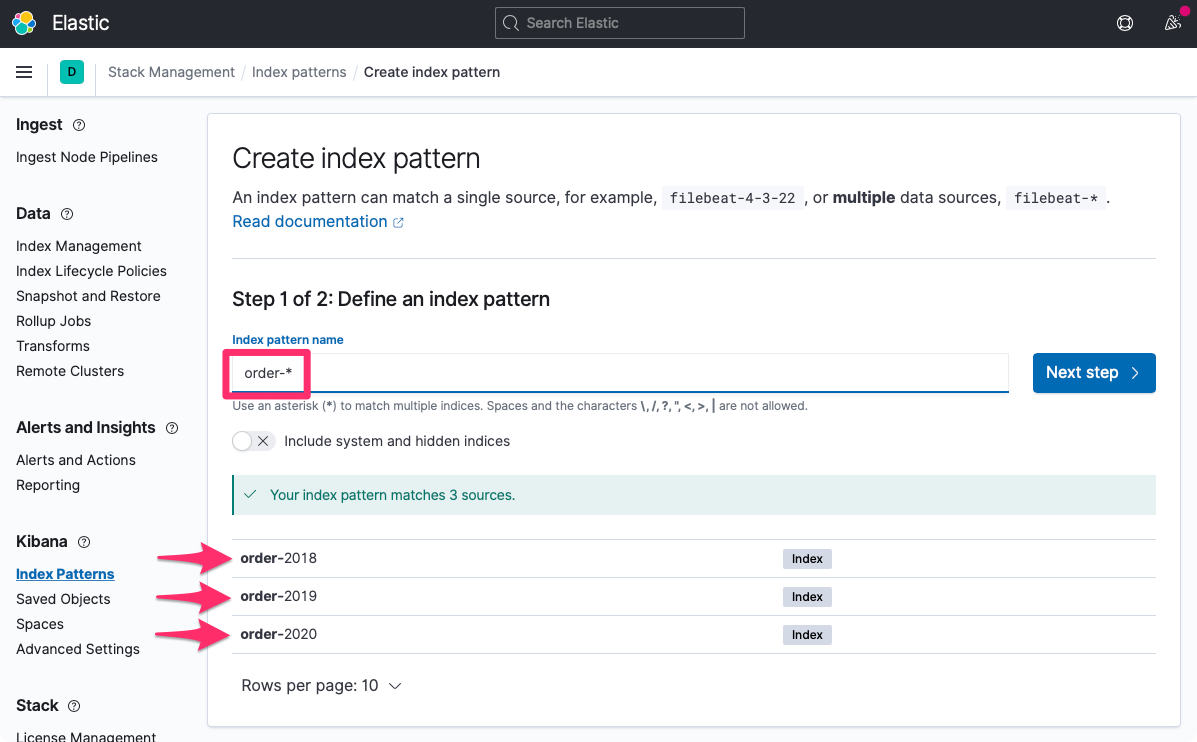
Často se znak * používá u indexů, které mají společný prefix. Předpokládejme indexy s objednávkami, přičemž každý rok se vytváří nový index - order-2018, order-2019, order-2020. Pokud bychom chtěli vyhledávat ve všech těchto indexech, bylo by to možné takto:
xxxxxxxxxxGET order-*/_search
Toho lze využít i při vytváření index pattern v Kibaně:
Smazání indexu
Smazáním indexu dojde také ke smazání všech dokumentů a veškerého nastavení, které obsahuje. V requestu stačí uvést název indexu:
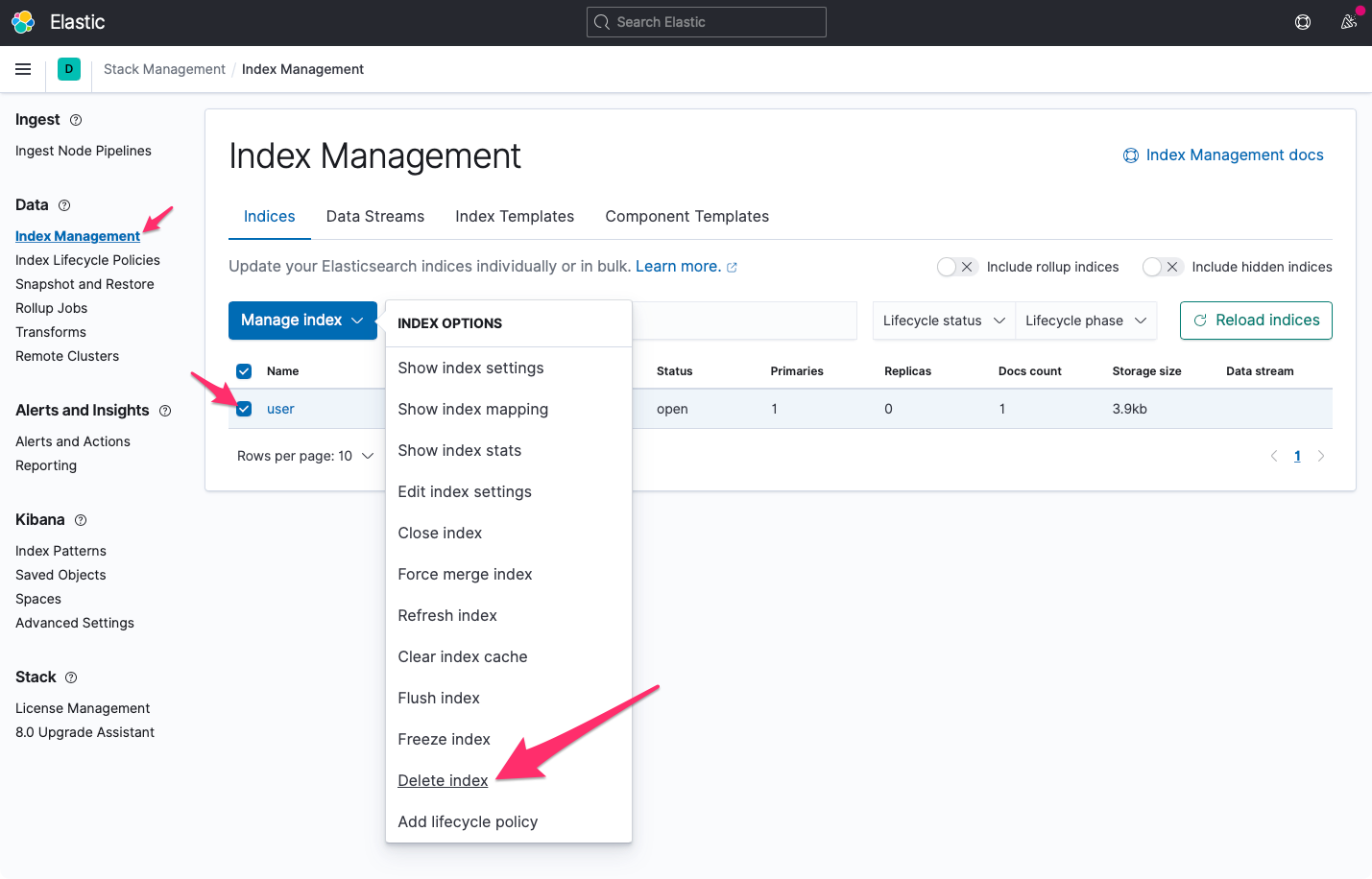
xxxxxxxxxxDELETE userAlternativně je možné smazat index prostřednictvím grafického rozhraní Kibany:
Úkol: Indexy, aliasy, reindexace
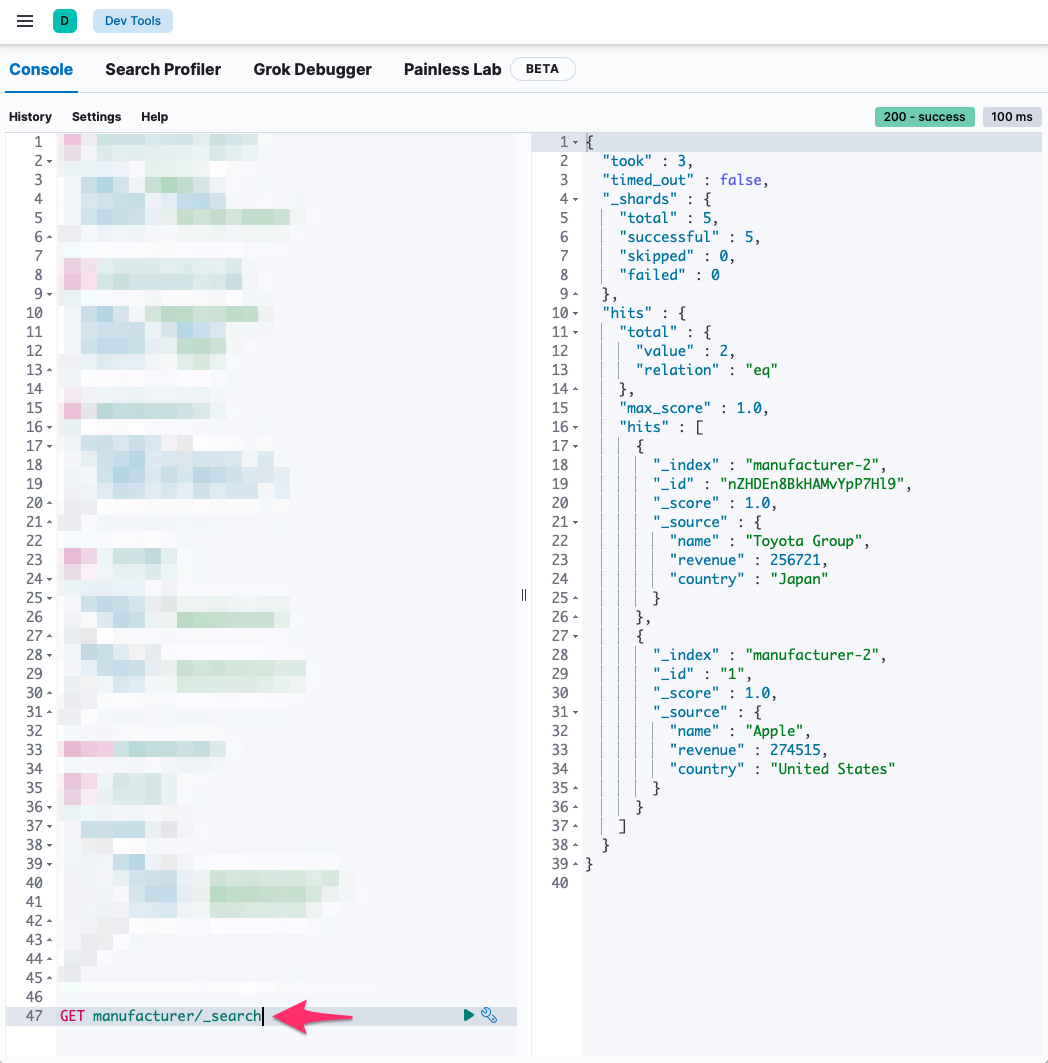
Vytvořte dokument v indexu
manufacturers ID1a atributy:name:Applerevenue:274515country:United States
Vytvořte další dokument v indexu
manufacturer- ID tentokrát nechte vygenerovat Elasticsearch:name:Toyota Grouprevenue:256721country:Japan
Nyní si představte, že se výrazně zvýšilo vytížení indexu a je nutné mu nastavit více shardů.
Vytvořte nový prázdný index
manufacturer-2s nastavením:Počet primary shards (
index.number_of_shards):5Počet replica shards
index.number_of_replicas:1
Reindexujte data z indexu
manufacturerdomanufacturer-2Smažte index
manufacturerVytvořte alias
manufacturer, který směřuje do indexumanufacturer-2Vypište všechny dokumenty v
manufacturer: